まるで暗号解読…データに潜む本質を暴きだす方法

スマートフォンやPCは、毎日あなたの趣味嗜好をブラウザの向こうにいる誰かに報告し、そのフィードバックとして一日に何十回とあなた好みの商品を紹介してくる。これが全世界の何十億人に起こっていることだとすると、どれくらいのデータがネット上を行き来しているのか…想像するだけで気が遠くなりそうだ。
そんな膨大なデータの洪水を日々処理し続ける役割を背負っているのはAI(人工知能)である。AIは、日進月歩でその性能を向上させている。SF映画のように、AIによって人類が滅ぼされることは恐らくない(永遠にないことを祈る)だろうが、限られた局面ではすでに人間を上回り、事業にも生活にも欠かせないパートナーとなっている。
しかしながら、その役割を広げる一方で、ぶつかる問題がひとつある。
それは処理すべきデータの量だ。
増え続ける世界のデータ流通量と
データに“意味を持たせる”必要性日本貿易振興機構(JETRO)によれば、2017年の全世界のデータ流通量は1217億ギガバイト(=122エクサバイト)に達したという。これはDVDに換算すると実に304億枚相当というちょっと信じられないような数値である。さらに2021年には2017年の2.3倍である278エクサバイトまで増えると予測されている。高速で大容量のデータ転送を可能にする5Gに代表されるような通信システムが発達してきているため、これからも増えていくに違いない。
データ量が多くなりすぎた時、AIが素早く処理するためにはどうしたらよいのか。単純な方法としては頭脳(CPUなど)を大きくするか、AIに渡すデータ量を少なくするか、の2つが考えられる。
「データは数字の羅列。それを実際に何かに役立てようとする場合、統計的手法を用いて“意味づけ”をしないと理解しにくいでしょう」と話すのは、静岡理工科大学でサービス情報学研究室を主宰する山岸祐己講師だ。
山岸氏によれば、AIの研究開発では様々な分野で性能の頭打ちが懸念されているという。世に出ているAI・機械学習手法は非常に優秀ではあるが、入力されるデータの“特徴量”が乏しいと十分な性能が発揮できない可能性が高くなる。つまり、ただデータの総量が多ければよいというわけではなく、データの中に使える情報がいかに詰まっているかが重要ということである。人間ですら意味(変化)が読み取りにくいようなデータは、AIにとっても処理が難しいものだ。
山岸氏は「データは人が直感的に意味…つまり“変化”を読み取れるような形に変換してから利用することで、AI・機械学習の可能性は広がるのではないか」と考えている。
「小さくとも重要な変化」はグラフ化できる?
転換点をあぶりだす統計手法とは最近の統計学でなくとも、1947年に発表された「順位和検定」など過去の知見は現代に活かすことができる、と山岸氏は言う。
例えば、2020年の上半期に静岡県のあるガソリンスタンドで顧客の分析実験を行ってみた。顧客の種類を、正会員(常連に近い)、無料会員(一見さん含む)、非会員(ほぼ初来店)、企業会員と4つに大別し、その来店パターンを調べた。2020年の新型コロナウイルス禍による経済活動の停滞のさなかに登場した「GoToキャンペーン」で、県外ナンバー車の流入が増えた時期でもあった。
そんな膨大なデータの洪水を日々処理し続ける役割を背負っているのはAI(人工知能)である。AIは、日進月歩でその性能を向上させている。SF映画のように、AIによって人類が滅ぼされることは恐らくない(永遠にないことを祈る)だろうが、限られた局面ではすでに人間を上回り、事業にも生活にも欠かせないパートナーとなっている。
しかしながら、その役割を広げる一方で、ぶつかる問題がひとつある。
それは処理すべきデータの量だ。
増え続ける世界のデータ流通量と
データに“意味を持たせる”必要性日本貿易振興機構(JETRO)によれば、2017年の全世界のデータ流通量は1217億ギガバイト(=122エクサバイト)に達したという。これはDVDに換算すると実に304億枚相当というちょっと信じられないような数値である。さらに2021年には2017年の2.3倍である278エクサバイトまで増えると予測されている。高速で大容量のデータ転送を可能にする5Gに代表されるような通信システムが発達してきているため、これからも増えていくに違いない。
データ量が多くなりすぎた時、AIが素早く処理するためにはどうしたらよいのか。単純な方法としては頭脳(CPUなど)を大きくするか、AIに渡すデータ量を少なくするか、の2つが考えられる。
「データは数字の羅列。それを実際に何かに役立てようとする場合、統計的手法を用いて“意味づけ”をしないと理解しにくいでしょう」と話すのは、静岡理工科大学でサービス情報学研究室を主宰する山岸祐己講師だ。
山岸氏によれば、AIの研究開発では様々な分野で性能の頭打ちが懸念されているという。世に出ているAI・機械学習手法は非常に優秀ではあるが、入力されるデータの“特徴量”が乏しいと十分な性能が発揮できない可能性が高くなる。つまり、ただデータの総量が多ければよいというわけではなく、データの中に使える情報がいかに詰まっているかが重要ということである。人間ですら意味(変化)が読み取りにくいようなデータは、AIにとっても処理が難しいものだ。
山岸氏は「データは人が直感的に意味…つまり“変化”を読み取れるような形に変換してから利用することで、AI・機械学習の可能性は広がるのではないか」と考えている。
「小さくとも重要な変化」はグラフ化できる?
転換点をあぶりだす統計手法とは最近の統計学でなくとも、1947年に発表された「順位和検定」など過去の知見は現代に活かすことができる、と山岸氏は言う。
例えば、2020年の上半期に静岡県のあるガソリンスタンドで顧客の分析実験を行ってみた。顧客の種類を、正会員(常連に近い)、無料会員(一見さん含む)、非会員(ほぼ初来店)、企業会員と4つに大別し、その来店パターンを調べた。2020年の新型コロナウイルス禍による経済活動の停滞のさなかに登場した「GoToキャンペーン」で、県外ナンバー車の流入が増えた時期でもあった。
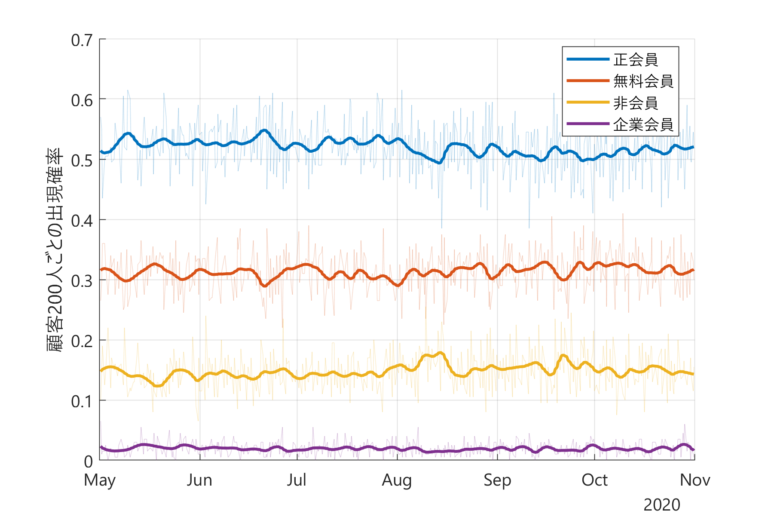
上の図は、顧客200人ごとの各会員の出現確率のグラフだ。青は正会員、赤は無料会員、黄色は非会員、紫は企業会員。どうだろうか?一目で何らかの変化が見てとれるだろうか?
一方で次のグラフを見て欲しい。
一方で次のグラフを見て欲しい。
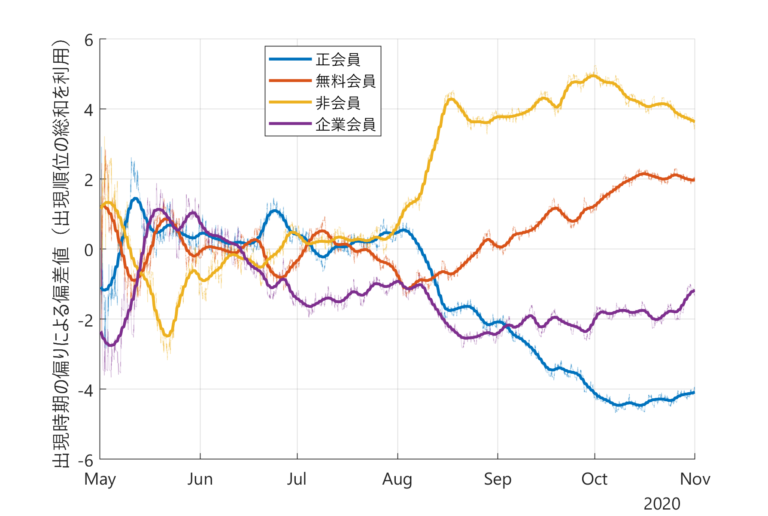
これは先述した「順位和検定」を利用した出現順位和による変換法を使用したグラフだ。従来のような人数ごとの出現確率ではなく、 データの並びを、最新の顧客を1位、最古の顧客を最下位としたランキングとして考え、全ての顧客種別を“順位が上位に偏っていればプラス、順位が下位に偏っていればマイナスになるよう偏差値化” した。つまり、このグラフは各顧客層の出現確率の増減をより明確にしたものと言えよう。あるタイミングを境に「非会員や無料会員といった常連ではない顧客の出現確率が増えたこと」が一目で分かる。「GoToキャンペーン」との因果関係を推し測ることができるのではないだろうか。
この2つのデータで、どちらがガソリンスタンドの来店顧客層の変化を可視化しているかは一目瞭然だ。もちろん、AIにとってもわかりやすいデータといえるだろう。このように、同じ数値データを使っても、きちんと整える方法がなければ宝の持ち腐れである。ビッグデータをどう処理するか、どうとらえるか、それがこれからの課題だ。
計算機が今ほど発達していなかった時代に生まれた「順位和検定」が、今このような形で利用されるとは…発案者は思ってもみなかったはずだ。山岸氏はこのオリジナルの手法を使ってAIをもっと進化させたいと考えている。
「自動運転をはじめIoT関連のプロジェクトなどは、まずデータ処理能力と送受信量の問題にぶつかります。過去の統計学的知見を用いて、最適なアルゴリズムを考案し、それらの問題を解決することがこれから重要になってくるでしょう」と山岸氏は言う。スマホ程度の計算機でも大量のデータを処理することができ、そこから送信すべき情報を抽出したり、元の情報をあまり崩すことなく圧縮したりすることが可能になれば、もっと多くのことができるようになる。
AIのポテンシャルを十分に引き出し、より良いサービス提供を実現するポイントは「データの前処理」にあると言えるだろう。
この2つのデータで、どちらがガソリンスタンドの来店顧客層の変化を可視化しているかは一目瞭然だ。もちろん、AIにとってもわかりやすいデータといえるだろう。このように、同じ数値データを使っても、きちんと整える方法がなければ宝の持ち腐れである。ビッグデータをどう処理するか、どうとらえるか、それがこれからの課題だ。
計算機が今ほど発達していなかった時代に生まれた「順位和検定」が、今このような形で利用されるとは…発案者は思ってもみなかったはずだ。山岸氏はこのオリジナルの手法を使ってAIをもっと進化させたいと考えている。
「自動運転をはじめIoT関連のプロジェクトなどは、まずデータ処理能力と送受信量の問題にぶつかります。過去の統計学的知見を用いて、最適なアルゴリズムを考案し、それらの問題を解決することがこれから重要になってくるでしょう」と山岸氏は言う。スマホ程度の計算機でも大量のデータを処理することができ、そこから送信すべき情報を抽出したり、元の情報をあまり崩すことなく圧縮したりすることが可能になれば、もっと多くのことができるようになる。
AIのポテンシャルを十分に引き出し、より良いサービス提供を実現するポイントは「データの前処理」にあると言えるだろう。

静岡理工科大学
山岸祐己 准教授
高度情報化社会は、情報過多社会という側面も持っており、様々な場所で重要な情報が埋もれてしまうという現象が起きている。既存のWebサービスだけでなく、現実世界のモノもインターネットに繋がり始めているため、新たなサービス分野でも同様のことが起こりつつある。これらの問題に対し、数理モデルとアルゴリズムを用いて情報の抽出・要約・可視化などを行い、人間の意思決定を助ける研究をしている。
山岸祐己 准教授
高度情報化社会は、情報過多社会という側面も持っており、様々な場所で重要な情報が埋もれてしまうという現象が起きている。既存のWebサービスだけでなく、現実世界のモノもインターネットに繋がり始めているため、新たなサービス分野でも同様のことが起こりつつある。これらの問題に対し、数理モデルとアルゴリズムを用いて情報の抽出・要約・可視化などを行い、人間の意思決定を助ける研究をしている。